Seit Anfang 2015 arbeite ich als AWS Cloud Consultant und sehe jede Menge kleine und mittelgroße AWS Umgebungen. Die meisten sind typische Web Applikationen. Ich will die 5 häufigsten Fehler zusammenfassen die mir dabei begegnen:
- Infrastruktur wird manuell verwaltet
- Auto Scaling Groups werden nicht überall verwendet
- CloudWatch-Metriken werden ignoriert
- Trusted Advisor wird nicht um Rat gefragt
- Virtuelle Maschinen werden nicht ausgelastet
Wenn du wissen willst wie du diese Fehler vermeiden kannst lese weiter.
Typische Web Applikation
Eine typische Web Applikation besteht mindestens aus:
- Load Balancer
- skalierbares Web Backend
- Datenbank
Das sieht üblicherweise wie folgt aus.
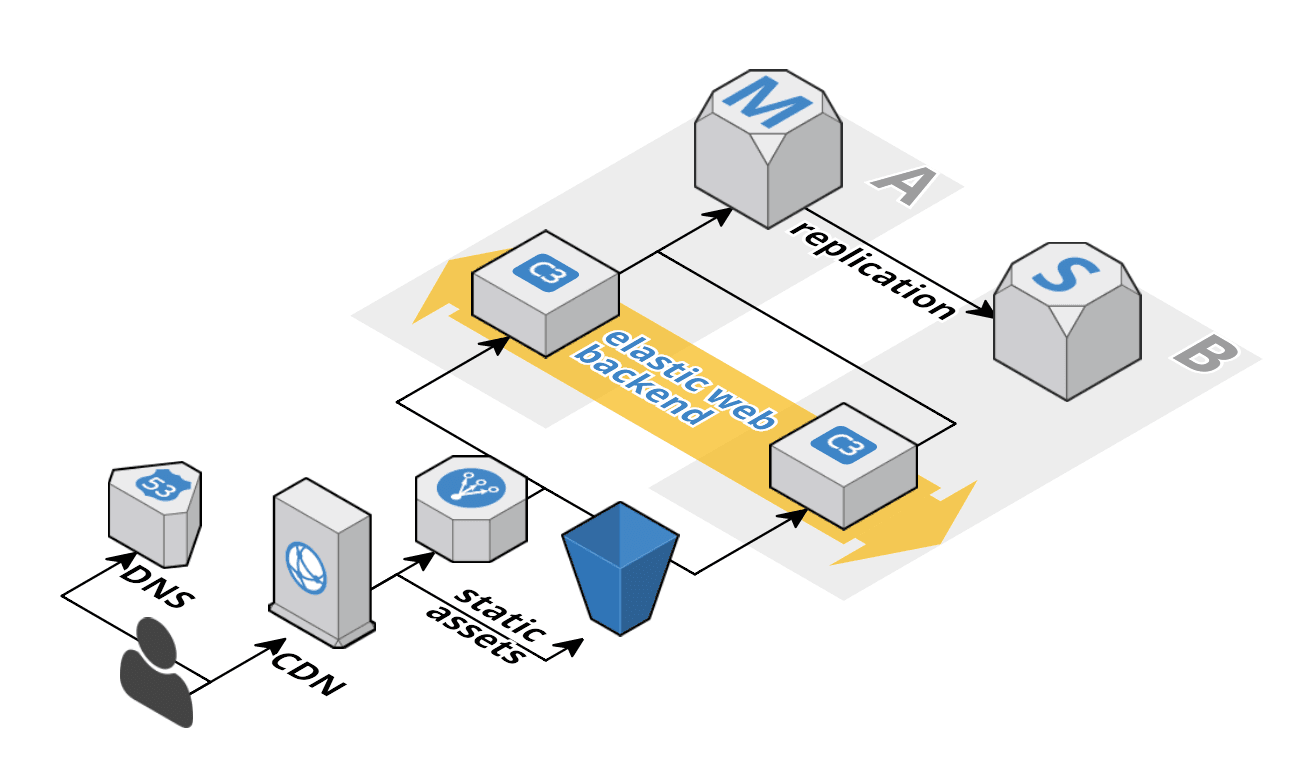
Diese Architektur ist de facto Standard. Wenn dein System anders aussieht solltest du einen guten Grund dafür haben.
Fehler 1: Infrastruktur wird manuell verwaltet
Wenn dein AWS Account über die webbasierte Management Console administriert wird dann verwaltest du Infrastruktur manuell. Die größten Probleme an dieser Methode sind: Nicht reproduzierbar, nicht dokumentiert und fehleranfällig. Glücklicherweise löst AWS CloudFormation genau dieses Problem. Und zwar kostenlos! Statt alle AWS Ressourcen (z. B. EC2 Instanzen, Security Groups, Subnets, …) manuell zu erstellen beschreibst du sie in einem Template. CloudFormation findet dann heraus wie dieses Template in ein lauffähiges System umgewandelt werden kann. Dazu erstell CloudFormation alle Ressourcen in der richtigen Reihenfolge, wie die folgende Abbildung zeigt.
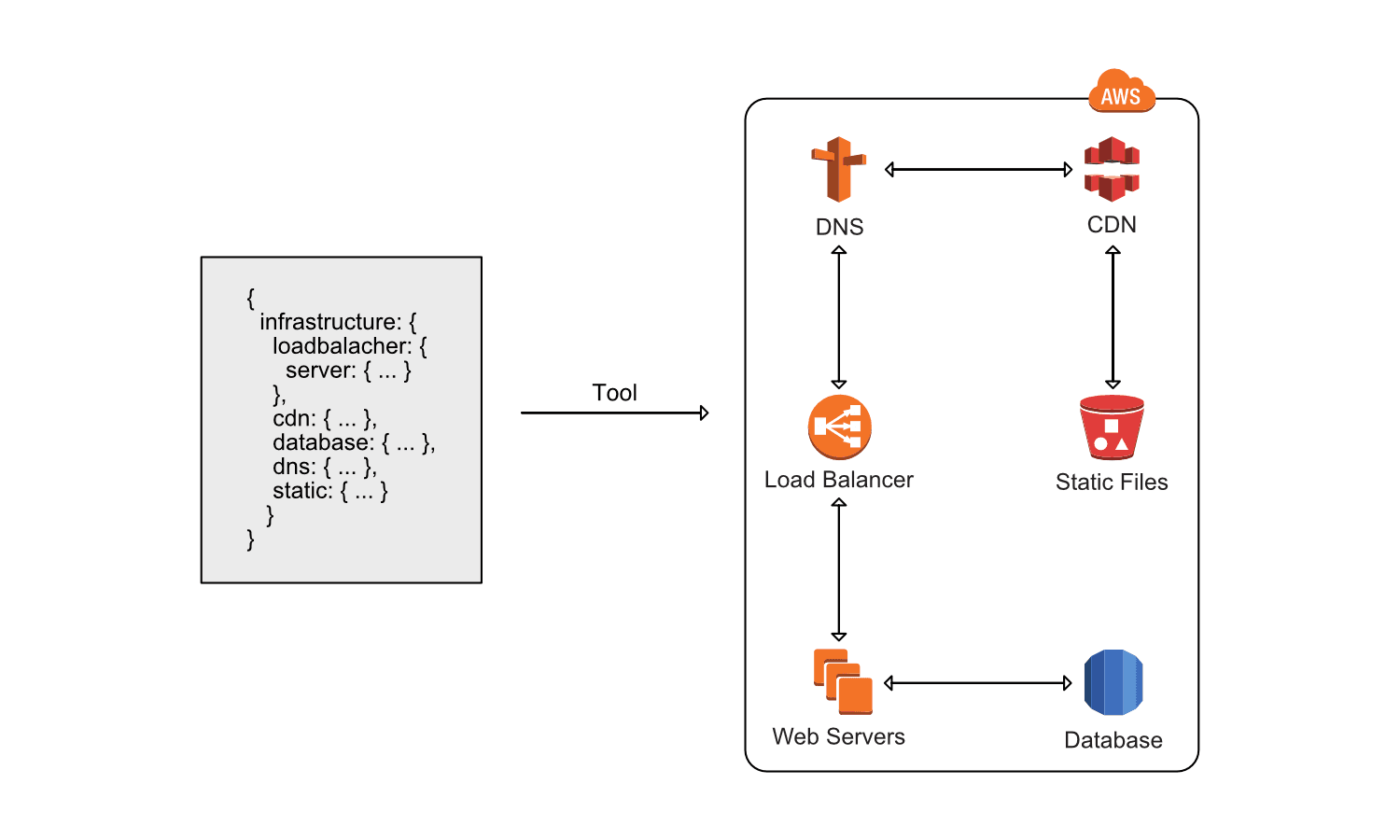
Du kannst sogar Änderungen an Templates auf bereits existierende Systeme anwenden. Eine typische Web Applikation kann einfach in ein Template verwandelt werden. Ein Beispiel für solch ein Template findest du unter github.com/AWSinAction. Wenn dich das Thema im Detail interessiert: ich habe ein Buch über AWS im Allgemeinen und CloudFormation im Speziellen geschrieben.
==Es gibt keinen Grund deine Infrastruktur manuell zu verwalten. Es ist unprofessionell und ein einziges Durcheinander!==
Fehler 2: Auto Scaling Groups werden nicht überall verwendet
==Das größte Missverständnis der Auto Scaling Gruppe ist, dass sie nicht nicht nur zum Vergrößern oder Verkleinern deine Server-Flotte verwendet werden kann!== Jede EC2 Instanz sollte in einer Auto Scaling Gruppe gestartet werden. Auch wenn es nur eine einzige Instanz ist. Die Auto Scaling Gruppe beobachtet deine Instanzen, ersetzt fehlerhafte Instanzen, bildet eine logische Einheit zur Verwaltung von mehreren EC2 Instanzen und ist kostenlos.
Für eine typischen Web Applikation sollten die Backend Server in einer Auto Scaling Gruppe verwaltet werden. Hauptsächlich kümmert sich die Auto Scaling Gruppe darum eine bestimmte Anzahl an funktionstüchtigen Server bereitzustellen. Der Auto Scaling Part wird dadurch erreicht, dass Alarme auf Metriken wie CPU Auslastung definiert werden die dann die Soll-Anzahl der funktionstüchtigen Servern in der Gruppe erhöht. Die Auto Scaling Gruppe passt dann den Ist-Zustand an den neuen Soll-Zustand an.
Fehler 3: CloudWatch-Metriken werden ignoriert
Jeder AWS Service schickt interessante Metriken an CloudWatch. Virtuelle Maschinen melden CPU-Auslastung, Netzwerk-Auslastung und Festplatten-Aktivität. Datenbanken melden Speicher- und IOPS-Auslastung. ==Dein Job ist es diese Metriken zu analysieren.== Schau dir die folgende CPU-Auslastung über einen Tag an.
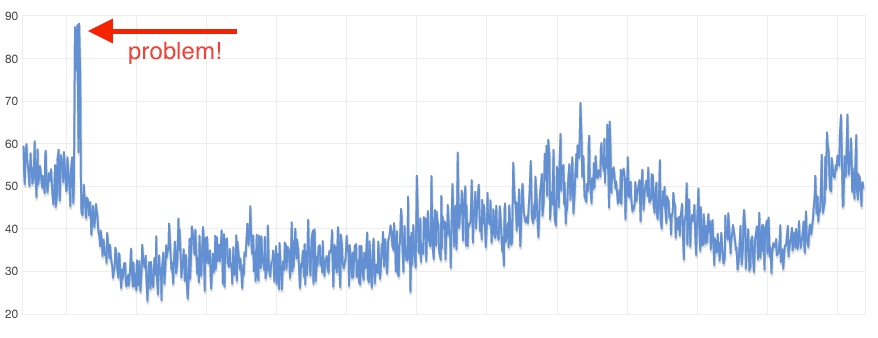
Der Zacken am Anfang des Tages konnte jeden Tag beobachtet werden. Immer zur selben Zeit. Riecht nach Cronjob? War ein Cronjob. Aber leider war das ein Web Backend. Jeden Tag war für eine kurze Zeit die Latenz des Systems deutlich höher wegen diesem Cronjob. Die Lösung war den Job auf einer extra Maschine laufen zu lassen. ==Solche Probleme lassen sich mit CloudWatch erkennen. Du musst nur die Metriken auswerten!==
Nachdem du mit deinen Metriken vertraut bist folgt der zweite Schritt: Alarme definieren. So überwachst du in Zukunft das System automatisiert. Bitte die Reihenfolge nicht vertauschen!
Fehler 4: Trusted Advisor wird nicht um Rat gefragt
Kennst du den Trusted Advisor? Er checkt deinen AWS Account und prüft ob du dich an bewährte Vorgehensweisen hältst. Im Fokus stehen:
- Kosten
- Leistung
- Sicherheit
- Ausfallsicherheit
Wenn dein Trusted Advisor Dashboard aussieht wie die folgende Abbildung gibt es Arbeit für dich.
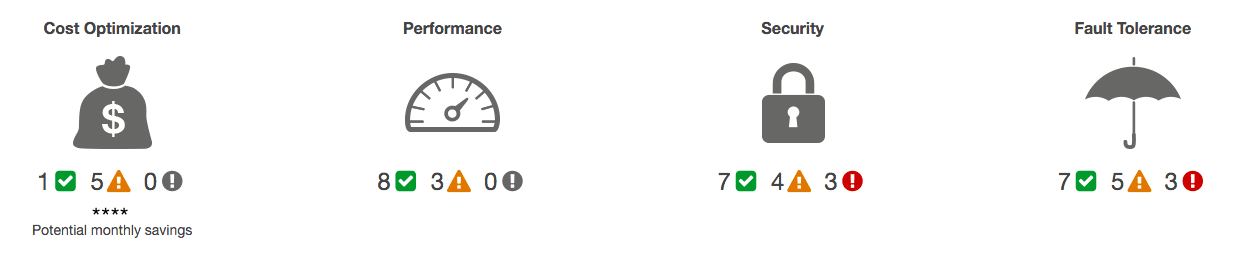
==Ich empfehle dir dich zuerst um Sicherheit zu kümmern!== Der Trusted Advisor kann dir eine wöchentliche E-Mail schicken. Dazu in den ** Preferences** deine E-Mail hinterlegen. Wenn du Business Support in deinem AWS Account wird der Trusted Advisor deutlich umfangreicher.
Fehler 5: Virtuelle Maschinen werden nicht ausgelastet
==Es gibt keinen Grund - außer manuell verwaltete Infrastruktur - EC2 Instanzen nicht zu verkleinern (sowie Anzahl der Maschinen als auch c3.xlarge zu c3.large) wenn diese nicht ausgelastet sind.== Woher weißt du ob deine EC2 Instanzen ausgelastet sind oder nicht? CloudWatch! So einfach ist es. Wenn du Auto Scaling Gruppen mit Scaling Rules benutzt prüfe ob deine Regeln zu früh / spät anschlagen.
Zusammenfassung
Als AWS Cloud Consultant sehe ich viele AWS Accounts. Während der letzen 12 Monate habe ich Fehler gesammelt die mir häufig begegnet sind. Die 5 häufigesten Fehler auf AWS sind:
As an AWS Cloud Consultant I see many AWS accounts. During the year I collected mistakes that I saw in each account and aggregated them to provide you my best of. It turned out that the 5 most common mistakes on AWS are:
- Infrastruktur wird manuell verwaltet
- Auto Scaling Groups werden nicht überall verwendet
- CloudWatch-Metriken werden ignoriert
- Trusted Advisor wird nicht um Rat gefragt
- Virtuelle Maschinen werden nicht ausgelastet
Jetzt ist es an dir deinen AWS Account zu prüfen.

